Week 4: Implementing a Mixture of Experts (MoE) and Program of Experts (PoE) Architecture
Building on the research and planning from Week 3, this week’s development focused on implementing the Mixture of Experts (MoE) and Program of Experts (PoE) architecture for the tv.llm module. These architectures were chosen to help with the reliability of translating natural language commands into executable Tölvera code by delegating specific tasks to specialized agents.
The transition from research to implementation revealed several practical challenges that weren’t apparent during the planning phase, particularly around getting consistent structured output from local language models and managing the communication between multiple specialized agents.
MoE Architecture and Rationale
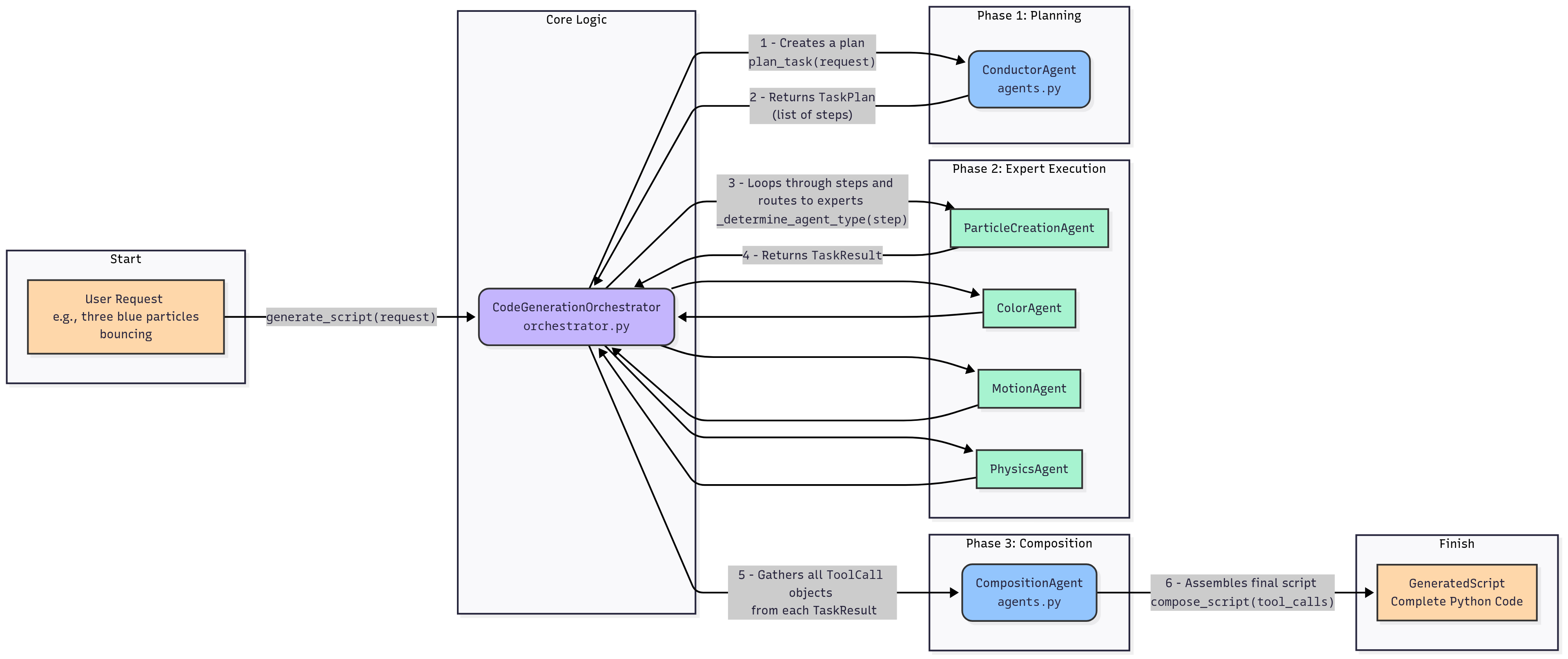
The implemented system is managed by a CodeGenerationOrchestrator, which acts as a central controller, routing tasks to a series of specialized agents. This approach was chosen over a monolithic architecture to help with reliability, modularity, and hopefully an easier way to debug if a Tölvera sketch wasn’t correct, where the problem stemmed from.
The current agent roster includes the following:
ConductorAgent: Responsible for initial task planning and breaking down the user’s request into a sequence of actionable steps.ParticleCreationAgent: Handles all aspects of particle generation, from quantity to shape.ColorAgent: Manages the color properties of the particles (this is non-trivial for the LLM based on the model choice)MotionAgent: Defines the velocity and movement patterns.PhysicsAgent: Implements complex behaviors like bouncing or flocking.CompositionAgent: The final agent in the chain, which assembles the code snippets from the other agents into a complete, executable Tölvera script.
Interaction Bit
Here’s a visual depiction of the flow of information to make this a bit easier to see
Challenges in Implementation
A significant challenge encountered this week was getting reliable, structured output from the local language models. We are still using pydantic-ai as a framework for defining the expected JSON schema which helped, but I often had to had the LLM re-generate the task 1 or 2 times before we got something that worked out.
To mitigate issues with model hallucination and inconsistent JSON formatting, the prompts became a bit tedious. They include not only the schema definition but also few-shot examples, and explicit positive and negative examples of correct and incorrect output to try and steer the generation to the correct output.
Model Issues Present
- Ollama and Pydantic-AI don’t necessarily work nicely together as you’d think. See https://github.com/pydantic/pydantic-ai/issues/582. Ollama has it’s own way of dealing with this through
structured outputshttps://ollama.com/blog/structured-outputs.